
There are a lot of ways to draw diagrams for availability and scalability. I use different ones for different purposes all the time. However, when I was reading the Art of Scalability by AKF partners I ran across a nice compound diagram they call the AKF Scale Cube which helps simplify the explanation of the multi-dimensional nature of scalability issues in complex web application scenarios.
I’ve been using this visualization model to help me explain how things fit together in both technical and business discussions. It comes in very handy I must say.
Most recent I’ve been using it to describe a gnarly distributed application I’m working on for a client. What follows is a generalized version of a functional use and some discussion of a compound view of ones I have created for clients of mine.
I’ve been using this visualization model to help me explain how things fit together in both technical and business discussions. It comes in very handy I must say.
Most recent I’ve been using it to describe a gnarly distributed application I’m working on for a client. What follows is a generalized version of a functional use and some discussion of a compound view of ones I have created for clients of mine.
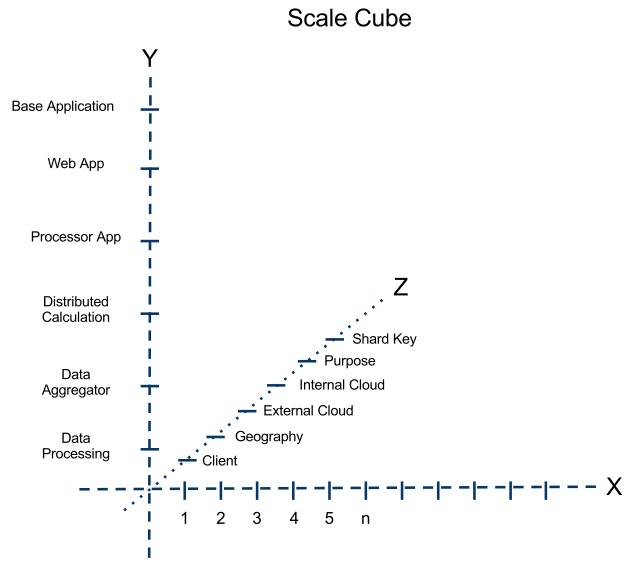
Some base-line definitions are in order if you haven’t read the book mentioned above.
X-Axis - Horizontal Scalability, Clones, Scale Out. These are terms often associated with the X-Axis. In the case of this graph, day you build a data processor then make 10 copies of it. Well, that’s scaling to 10 units on the x-axis in this graph. Depending on your application, this can help you increase your capacity; but not always!
Y-Axis - I’ve called this axis functional decomposition for a long time. It can be thought of as breaking the application down from a monolithic single instance into discreet stand-alone parts. I have some examples that are a bit of mix from various projects I’ve worked on in the past here.
Z-Axis - This is the tricky one for most folks. This is what people might call sharding, partitioning, etc. Keep in mind, I’m not only talking about a database here. I’m talking about an entire complex multi-faceted distributed highly-available web application.
0,0,0 - The intersection of all three axis or 0,0,0. This is what some would call an all-in-one server. It’s often used for proof of concept for for launching without a care in the world for future growth needs. There’s nothing wrong with it as long as you understand the limitations and technical debt associated with the approach.
Z-Axis Item Explanations
Client - Assuming this is a multi-tentant application you may want to shard your application by client such that each client or group of clients is assigned somehow to a specific cluster of nodes.
Geography - Assuming you’d like to have built in DRBC and your applciation is capable of surviving being split up into many pieces then you could end up sharding your application by data center and broader geographies such as city, state, country.
External Cloud - Using IaaS and PaaS resources outside of your own data centers. For a refresher on IaaS and PaaS see the article I wrote, “Cloud Computing: Get Your Head in the Clouds,” in 2008 that was heavily read over the years.
Internal Cloud - Using your own infrastructure resources BEHIND your own firewall to do whatever it is that your application does. This doesn’t always have to be a cloud. If you want to know what I think it takes to be a cloud then read the several articles I wrote over the years related to that topic. I do set the bar pretty high though I’ve learned.
Purpose - You might want to simply partition along the Z-Axis by any generic purpose for various reasons. I think of this a little bit like saying I want to put all widgets in data node 1 and all waggles in data node 2. They’ll both fit in a single node but maybe I want to spread my risk around. This one is a little nebulous but it can engender fun conversations about why things need to exist at all.
Shard Key - We see this all the time in traditional RDBMS style deployments and even in some of the newer tools in the NOSQL world. It’s basically just some index of what node you put things one somewhere. For those of you that had to deal with libraries before the internet you’ll remember the lovely card catalog. It’s was nicely set up to help you figure out with shard of the library your book was close to. Then, when you got there, good old dewey decimal system kicked in to take you the rest of the way.
Y-Axis Item Explanations
Data Processing - this could be some application that transforms data from one state to another. For example, it might simply remove all the spaces in a document and replace them with dashes. That’s a bit of a silly example, but just to make the point.
Data Aggregator - I’ve had to build project after project that needed one form or another of data aggregation. So, just think of this as something that might consume and RSS feed and stick it in a database of some kind.
Distributed Calculation - I’ve been doing work and research with Map-Reduce, Actor Models, the Bulk Synchronous Parallel Model and more exotic instruments from past, present, and future. This is simply something that does some kind of math or calculation of some sort. For example, counting all the uses of the word onomatopoeia in 50TB of English essays by high school students across 100’s of of compute nodes.
Processor App - This is just a generic discreet application that processes something, like an API request for example.
Web App - This is an application, in my case, written in a modern MVC framework that has the job of interacting with web users and getting things done in the back-ground in various ways with various services.
Base Installation - I think of this as just shared code. One of the developers I have been working with recently suggested that we extract a number of commonly used components from various application pieces on the Y-Axis and build a library of sorts. Great suggestion in this case, so I stuck in on my general diagram to remind me in the future.
What’s interesting about all these conceptual applications is that if you create them correctly and with the correct architectural models that each item that lives on the X Axis will also be able to scale on the X and Z axis. For example, you could have your web application running 5 X-Axis copies in 4 Y-Axis partitions; say external cloud, by client, purpose, and by geography per client. So, you’d end up use four AWS Availability zones in 2 AWS locations running 96 application nodes in total. Of course, your application has to be built correctly to take advantage of all of this distribution at every level. But, that’s a topic for a later date I suppose.
In summary, this post was just to share some of my thinking around the use of a very nice visualization tool by the fine folks at AKF Partners. So, a shout out to them for the nice tool and hopefully this helps people a bit understand how it can be used / thought of in a variety of ways.
Just remember, it's not one-size-fits all. Your use, labels, and needs for such things will vary greatly depending on what you are trying to architect, develop, and deploy.